Scene Classification
The 15 class scene dataset was gradually built. The initial 8 classes were collected by Oliva and Torralba [43], and then 5 categories were added by Fei-Fei and Perona [49]; finally, 2 additional categories were introduced by Lazebnik et al. [25]. The 15 scene categories are office, kitchen, living room, bedroom, store, industrial, tall building, inside cite, street, highway, coast, open country, mountain, forest, and suburb. Images in the dataset are about 250*300 resolution, with 210 to 410 images per class. This dataset contains a wide range of outdoor and indoor scene environments.There are a lot of works tested on this dataset, but most of them focus on dictionary learning, quantization method and classification methods. Meanwhile, most of them used spatial pyramid matching(SPM) [25]. It is widely recognized that whole spatial layout information is effective on this dataset. However, here, in order to directly compare different features and methods, we don't apply SPM. Unlike the flower and leaves datasets, Scene 15 doesn't have strong shape structure, thus, here, we just use two templates and the dimension of PRI-CoLBPg is 1180.
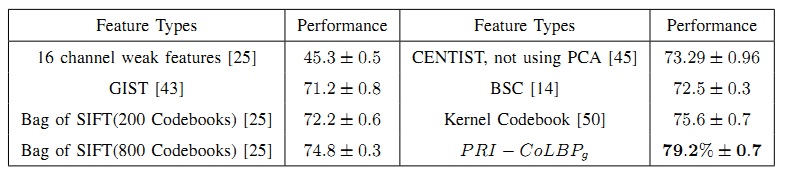
State-of-the-arts Methods: For scene classification, we have compared with several widely used features and methods. Bag-of-words method is the most popular method for scene classification. In the paper [25], Lazebnik etc al. compared the performance between the strong feature and weak feature, where SIFT is recognized as a strong feature and oriented edge point is recognized as weak feature. GIST [43] is a famous feature for scene classification because of its efficiency and effectiveness on scene classification. Since GIST is designed to capture spatial layout, so here, we just follow the original method and use 512 dimensions' GIST feature. In the scheme of bag-of-words, instead of using hard assignment, kernel codebook [50] was applied for quantization encoding. Recently, Wu etc al. proposed a feature called CENTRIST for scene classification, which is similar to LBP in nature. Instead of using bag-of-words model and SVM classifier, Rasiwasia etc al. proposed to use bayes method for scene classification. They proposed to capture semantic co-occurrence into the bayes scheme. Here, we abbreviate this method as BSC. The experimental results have been shown below. All related results are cited from original paper except GIST which is based on the standard implementation from the original authors' website.

Experimental Analysis:
Table up shows the detailed resutls of classification experiments using 100 images per class for training and the rest for testing. Compared with BoW model, PRI-CoLBPg achieves 79.2% which significantly outperforms BoW with weak features 45.3% and also outperforms BoW with 400 codebook using SIFT feature 74.8%. Meanwhile, PRI-CoLBPg also outperforms kernel codebook method and improves the performance from 75.6% to 79.2%. Compared with GIST feature and CENTRIST, PRI-CoLBPg obviously outperforms both of them. Furthermore, compared with bayes method [14] with SIFT feature, PRI-CoLBPg also outperforms it and improves it 6.7%.
It has been indicated in [45] that GIST works well on outdoor categories and performs pool on indoor categories. For our PRI-CoLBPg, it works well on both indoor and outdoor categories. Besides of the great effectiveness, PRI-CoLBPg is also greatly efficient. It should noted that it takes about 0.07 second for PRI-CoLBPg processing an image in Scene 15 data set.
References
[14] N. Rasiwasia and N. Vasconcelos, “Holistic context modeling using semantic co-occurrences,” CVPR, 2009.[25] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories,” CVPR, 2006.
[43] A. Oliva and A. Torralba, “Modeling the shape of the scene: A holistic representation of the spatial envelope,” IJCV, 2001.
[45] J. Wu and J. Rehg, “Centrist: A visual descriptor for scene categorization,” PAMI, 2011.
[49] L. Fei-Fei and P. Perona, “A bayesian hierarchical model for learning natural scene categories,” CVPR, 2005.
[50] J. C. van Gemert, C. J. Veenman, A. W. M. Smeulders, and J. M. Geusebroek, “Visual word ambiguity,” PAMI, 2009.